¿Cómo se clasifican las imágenes obtenidas por satélite? Te lo explicamos en detalle en este extracto de texto, extraído de uno de los módulos del “Curso de Teledetección aplicada a Hidrogeología“.
El propósito de los procedimientos de clasificación de imágenes de satélite es categorizar automáticamente todos los píxeles en una o diversas clases temáticas. Esta información categorizada se utiliza posteriormente para generar mapas temáticos. En este caso, el patrón espectral presente dentro de la información de cada pixel se usa como una base numérica para la categorización; es por ello que diferentes tipos de objetos presentan diferentes combinaciones de ND (números digitales) basados en su inherente reflectancia espectral y propiedades de emisividad. Existen diferentes tipos de patrones que permiten la categorización de los pixeles de una imagen, como ser patrones espectrales, temporales y espaciales.
Los métodos de clasificación se dividen usualmente en dos tipos, en función de la manera en la que se obtienen las estadísticas de las categorías definidas durante la fase de entrenamiento: métodos supervisados y métodos no supervisados. Independientemente del método usado, es importante que la clasificación tenga las siguientes características: a) fiable, b) reproducible por otros, dadas las mismas variables de entrada c) robusta, no sensible a pequeños cambios en las condiciones de entrada, d) objetiva, que no esté marcado por las decisiones del intérprete. Es importante que en este último punto se entienda que el intérprete puede muchas veces tomar decisiones que resuelvan problemas relacionados con la categorización de coberturas siempre y cuando este proceso pueda ser reproducido por otros.
4.1. Clasificaciones no supervisadas
Es un clasificador que usa algoritmos para agregar píxeles en grupos naturales o clúster con características espectrales similares presentes en la imagen. En este tipo de proceso, el analista no interviene en el proceso de clasificación y no existen áreas de entrenamiento. Aunque los resultados son poco exactos, es un paso obligado porque sirve para que el intérprete pueda asociar tipos de coberturas a los clústeres generados con información auxiliar.
Cuando se realiza éste proceso hay que comprobar una a una cada correspondencia entre la clase espectral y la clase temática. Si existe la opción de introducir un número de clases, habrá que determinar el máximo de clases en función de las clases temáticas previstas y añadir otras situaciones circunstanciales como puede ser la presencia de nubes, nieve, zonas de sombra, etc.
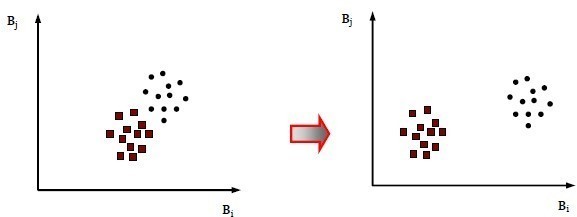
El Clustering o ISODATA es el algoritmo más utilizado que utiliza una ‘distancia espectral mínima’ para asignar a un conglomerado, un vector característico candidato (Figura 13).
Una vez que se tiene la clasificación no supervisada hay que analizar estadísticamente cada una de las clases resultantes. Comprobar las correspondencias entre clases espectrales y clases temáticas. El resultado de ésta clasificación nos puede servir para definir áreas de entrenamiento en una posterior clasificación supervisada (Figura 14).

4.2. Clasificaciones supervisadas
En el caso de las clasificaciones supervisadas, se requiere del conocimiento de la zona de estudio, adquirido por experiencia previa o por la realización de un trabajo de campo. Es decir, que el intérprete debe tener una gran familiaridad con el área de interés, para poder interpretar y delimitar sobre la imagen, áreas suficientemente representativas, denominadas áreas o regiones de interés (ROI por sus siglas en inglés), de cada una de las categorías representadas y que forman parte de la leyenda. Los pasos básicos para realizar una clasificación supervisada son los siguientes:
- Etapa de entrenamiento: en esta etapa el intérprete identifica áreas de entrenamiento representativas, y genera una descripción numérica de los atributos espectrales de cada categoría de cobertura de la tierra por escena.
- Etapa de clasificación: Cada píxel es categorizado y asociado a una determinada categoría de la leyenda de acuerdo a su mayor semejanza. En el caso que el píxel sea insuficientemente similar, este se catalogará como “desconocido”.
- Etapa de análisis de precisión y verificación de resultados: La estimación de la exactitud de una clasificación es el grado de concordancia entre las clases asignadas por el clasificador y los datos tomados en el terreno obteniendo una estimación más realista de los errores siempre y cuando la muestra de pixeles sea lo suficientemente
4.2.1. Etapa de entrenamiento
La clasificación supervisada contempla los procedimientos de agrupación de los píxeles de una imagen conforme a su similitud espectral, el nivel de detalle y la leyenda temática, preestablecidos a priori. Para este fin sobre la imagen original se seleccionan y se delimitan los grupos de píxeles, que representan los patrones de diferentes clases temáticas (muestras). Es importante que la muestra sea homogénea, pero al mismo tiempo incluye la variabilidad espectral de cada clase temática. Se recomienda que el usuario adquiera más de un área de entrenamiento por clase temática, utilizando la información de campo, mapas y estudios existentes, entre otros.
Estas áreas para “entrenar” al programa de clasificación en el proceso de reconocimiento de las distintas categorías sirven para caracterizan cada una de las clases, de tal modo que más tarde se asignan el resto de los píxeles de la imagen a una de esas categorías en función de la similitud de sus ND con los extraídos como referencia. Para una delimitación más precisa de éstas áreas de entrenamiento, puede ser de gran ayuda los trabajos de campo y otros documentos auxiliares, como la fotografía aérea y la cartografía convencional, teniendo en cuenta que debe tratarse de ejemplos suficientemente representativos y homogéneos de la clase que pretende definirse. Además, es importante que exista un control de campo suficiente, en fecha próxima a la adquisición de la imagen para garantizar la consistencia entre lo medido en el terreno y por el sensor.
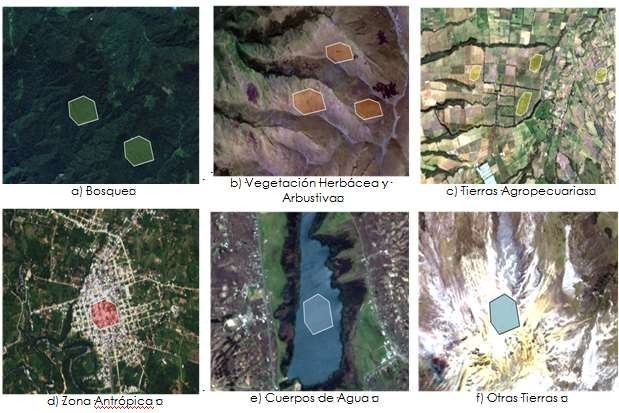
Para la toma de muestras es recomendable iniciar con los accidentes geográficos que son identificables a primera vista, como lo son el agua, hielo, nubes, suelo desnudo, bosque, para luego continuar con áreas arbustivas y herbáceas, áreas agropecuarias, y zonas antrópicas, entre otras (Figura 15).
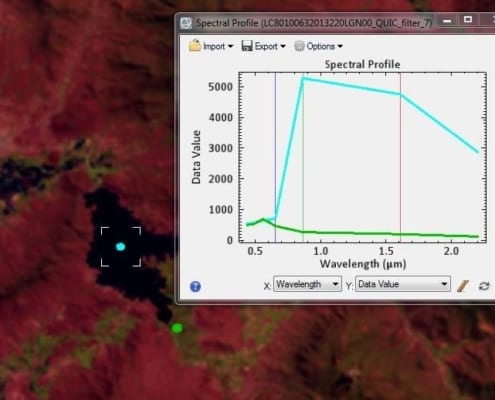
En general resulta conveniente seleccionar varias muestras por categoría, a fin de reflejar adecuadamente su variabilidad en la zona de estudio, sin embargo, se recomienda tomar sólo aquellas que sean fundamentalmente las más representativas para la categoría a la que pertenecen, y evitar en la medida de lo posible que existan muestras idénticas; de ser este el caso, estas deberían adjuntarse directamente a una muestra ya existente; esto ayudará a no tener un número excesivo de muestras, lo cual es un problema en procesos futuros (Figura 16).
En lugares donde existe presencia agropecuaria, es aconsejable delimitar el área tratando de seguir la forma de los diferentes tipos de cultivos, esto ayuda a homogeneizar la muestra y evitar que aparezcan los píxeles aislados dentro de la cobertura. Para la toma de muestra en vías, es aconsejable tomar muestras lineales para una mejor definición de las mismas, este método es recomendable para carreteras amplias, debido a que si se toman muestras en caminos angostos se corre el riesgo de incluir en esa categoría píxeles vecinos pertenecientes a una categoría distinta. Según sus criterios, utilice uno u otro método de recolección de regiones de interés para todas las clases temáticas. No olvidar que resulta más conveniente elegir varias áreas de pequeño tamaño que una sola de mayores dimensiones, ya que tenderá a infravalorarse la variabilidad de esa categoría.
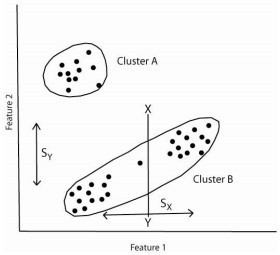
Una vez creadas las regiones de interés, se deben calcular las estadísticas elementales de cada categoría: media, rango, desviación estándar, histogramas, separabilidad, entre otras, a partir de los ND de todos los píxeles incluidos en las áreas de entrenamientos de esa clase. Lógicamente este cálculo se aplica a todas las bandas que intervendrán en la clasificación. En definitiva, se asume que las áreas de entrenamiento son fieles representantes de las distintas categorías, y que, por tanto, las medidas extraídas a partir de sus ND definen convenientemente a esas clases. De aquí que sea crucial su correcta selección, ya que de otro modo se estaría forzando al algoritmo a clasificar áreas heterogéneas. Cuanto más separables sean las firmas y/o clases espectrales hay menor confusión entre clases, y por tanto, será más fiable la clasificación (Figura 17).
Se debe proceder a realizar un análisis de separabilidad para discriminar mejor las clases a ser definidas. Esta opción evalúa la separabilidad espectral entre pares de muestras seleccionados, dando como resultado un reporte en donde se despliega el promedio de separabilidad tanto con el método de la Divergencia Transformada como el de Jeffries-Matusita.
Primero se calcula la divergencia a partir de la siguiente expresión:
![]()
i , j son dos firmas correspondientes a 2 clases,
Ci es la matriz de varianzas-covarianzas para la firma i
μi es el vector de medias para la firma i
La divergencia transformada será:
![]()
La escala de los valores varía entre 0 y 2. Si el valor resultante es mayor de 1.9, las clases son separables; y si son menores de 1.7 las clases son poco separables y habría que tomar nuevas muestras representativas.
4.2.2. Etapa de clasificación
La etapa final de la clasificación corresponde a la agrupación de los ND de toda la imagen alrededor de las clases temáticas definidas en el proceso de muestreo. Existen diversos procedimientos matemáticos para analizar los patrones espectrales por medio de la clasificación supervisada. El tipo de clasificación óptimo dependerá del tipo y procesado de la imagen, datos disponibles e información que se quiera identificar.
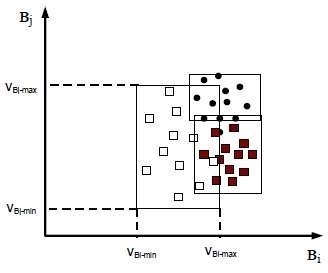
- La clasificación por Paralelepípedos permite señalar al usuario unos umbrales de dispersión asociados a cada clase. Consiste en determinar los valores máximos y mínimos para cada clase en cada banda. Los píxeles que se encuentren dentro de los valores envolventes son asignados a esa clase, en caso contrario quedan sin asignar (Figura 18).
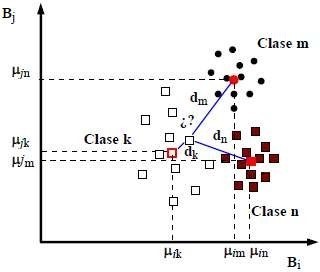
- La clasificación por Mínima distancia consiste en la determinación de las medias de cada La asignación se realiza hacia la clase con menor distancia. Algunos de los píxeles quedarán sin clasificar si se introduce una distancia máxima o una desviación estándar máxima (Figura 19).
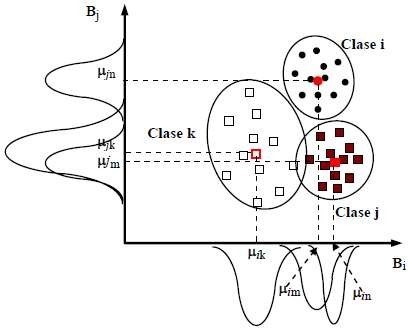
- En la clasificación de Máxima verosimilitud, el píxel se asigna a aquella clase con la que posee mayor probabilidad de pertenencia. Evalúa la varianza y covarianza de cada vector característico desconocido para asignárselo a una categoría espectral. Se crean elipses de ‘iso- probabilidad’ en el espacio de características. La forma y orientación de estas elipses expresa la sensibilidad del clasificador a la variabilidad y covarianza entre clases (Figura 20).
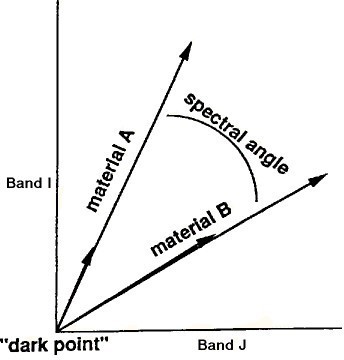
- En la clasificación Spectral Angles se considera que en un píxel puede haber más de una clase, siendo su nivel digital (ND) una combinación lineal de los distintos tipos de Por tanto, el ND de un punto será una mezcla de varios ND que corresponderían a las clases puras (end- members). El método clasifica los elementos de la imagen midiendo la separación angular entre un vector espectral de referencia y cada vector del píxel en un espacio n-D (Figura 21).
- Existe otro método que consiste en el Análisis de imágenes orientados a objetos (eCongition). Además de la información espectral, utilizan la textura y la información contextual contenida en la imagen en el proceso de clasificación. La imagen es segmentada o partida en objetos que forman las unidades de clasificación (Figura 22).
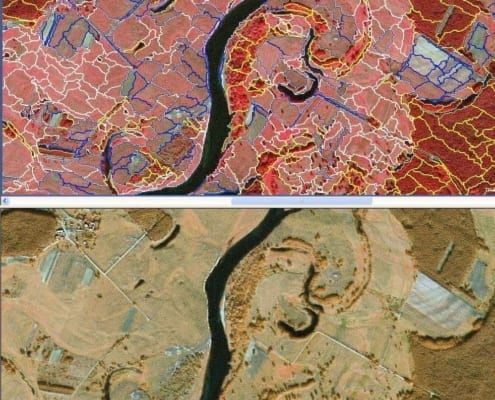
También se basa en la teoría borrosa o difusa, para la cual un objeto puede ser clasificado en más de una clase con diferentes valores de pertenencia. En éste análisis, las unidades básicas de procesado son segmentos u objetos imagen constituidos por conglomerados de celdas (clústeres).
4.2.3. Etapa de generalización de clasificaciones
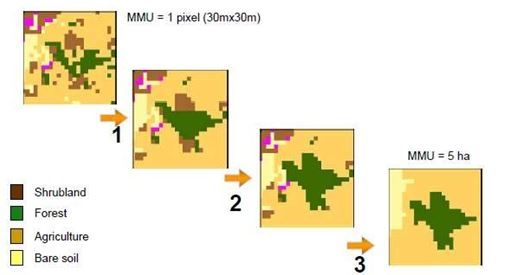
Las imágenes clasificadas presentan una falta de continuidad y coherencia espacial de las clases. Es recomendable suavizar la clasificación para mostrar únicamente las clases dominantes. En la imagen clasificada quedan una serie de píxeles aislados, los cuales en muchos casos no representan un área significativa, por lo que es recomendable aplicar un filtro con la finalidad de que las clases predominantes absorban estos píxeles. Algo que se debe tomar en cuenta al momento de hacer este proceso es la escala final del mapa. La aplicación de un filtro, en algunas ocasiones, es innecesaria, en especial cuando las muestras satisfacen la clasificación.
Al utilizar una imagen de alta resolución puede generar muchos píxeles aislados, que muchas veces el filtro no borra. Si el número de píxeles aislados es considerable, convendrá retornar a la fase de entrenamiento (muestreo), con objeto de deducir nuevas categorías o perfeccionar la definición de las ya existentes.
Se puede generalizar la imagen mediante filtros u operadores morfológicos (Figura 23):
- Clump Classes: agrupa clases en otras adyacentes.
- Sieve Classes: elimina los píxeles aislados agrupándolos por zonas.
- Filtro Majority: aplica una ventana móvil para poder definir la clase mayoritaria.
4.2.4. Etapa de análisis de precisión y verificación de resultados
El análisis de precisión es un paso fundamental durante el proceso de clasificación digital. La calidad hace referencia a la totalidad de las características de un producto que tienen que ver con sus aptitudes para satisfacer las necesidades explícitas e implícitas. En cartografía, se considera el control topológico y temático de la cartografía generada.
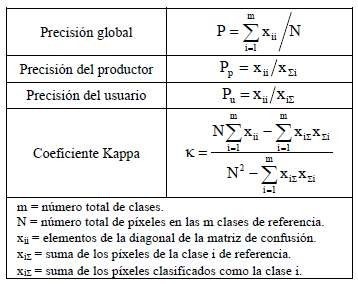
Un método apropiado para la evaluación es mediante matrices de confusión que compara los resultados de la clasificación frente a los datos de validación obtenidos en el campo, obteniéndose:
- Precisión global cuantificando el número de píxeles clasificados correctamente.
- Precisión del productor que establece la probabilidad de que un píxel de una determinada clase esté correctamente clasificado.
- Precisión del usuario que calcula la probabilidad de que un píxel clasificado como una clase determinada corresponda realmente a dicha clase.
- Coeficiente Kappa que calcula la correspondencia entre la imagen clasificada y la realidad según la exactitud de la clasificación y eliminando el factor azar.
Dado un muestreo aleatorio de puntos clasificados, los coeficientes que se miden para el análisis de precisión y la verificación de los resultados son: